Apache Spark is built around a central data abstraction called RDDs. RDD stands for Resilient distributed dataset, and each RDD is an immutable distributed collection of objects.
In this post we explore some of the transformations that can be applied to these RDDs to implement the traditional wordcount example. As a refresher wordcount takes a set of files, splits each line into words and counts the number of occurrences for each unique word.
Let us take a look at the code to implement that in PySpark which is the Python api of the Spark project.
import sys
from pyspark import SparkContext
sc = SparkContext(appName="WordCountExample")
lines = sc.textFile(sys.argv[1])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x,y:x+y)
output = counts.collect()
for (word, count) in output:
print "%s: %i" % (word, count)
sc.stop()
To run this code I assume you already have a running installation of spark on your local lab machine. If not you can head to my previous blog to Install Spark in 3 easy steps.
The command to submit this “Standalone application” using the Spark installation README.md file:
cd ~/spark-1.2.0-bin-hadoop2.4 # or wherever your Spark folder is ./bin/spark-submit wordcount.py README.md
The output should look like the following:
......... : 75 all: 1 help: 1 when: 1 automated: 1 Hadoop: 4 "local": 1 including: 3 computation: 1 ["Third: 1 file: 1 high-level: 1 find: 1 web: 1 Shell: 2 cluster: 2 how: 2 using:: 1 Big: 1 guidance .........
The main part of the code responsible for counting the words is:
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x,y:x+y)
This line involves three spark calls that do the work: flatMap, map and reduceByKey. To visualize the Transformations that these functions apply to the Initial RDD we can try to use the following diagram:
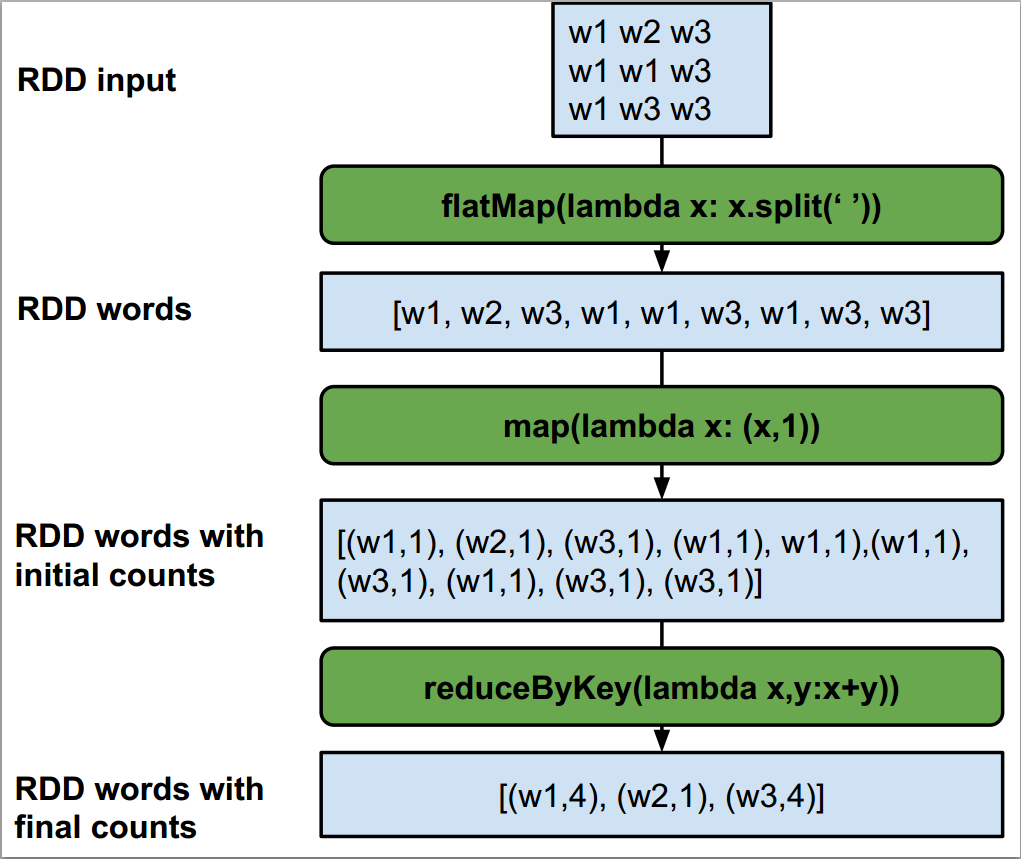
First, the flatMap function takes the input file that is returned by the sc.textFile function that returns the lines of the file. This flatMap does two things it applies the lambda function to each line, creating a list of space separated words. Then the second thing flatMap does by default is flattening the list of lists, meaning that [[w1,w2],[w2,w3]] becomes [w1,w2,w2,w3]
Second, a map function is applied to the resulting RDD that is produced by flatMap. The map operation applies the lambda function provided to each element in the RDD. Here each element is a word in the list of words RDD and the map produces a pair for each word composed of the word as the key and the initial count as of that word as 1.
Finally, the aggregation is performed with the reduceByKey function on the resulting RDD. This is similar to the regular reduce operation that takes two elements and applies a function to those two elements, but in this case the words are first grouped by key, which in the case of (w1,1) is the word part of the pair. This gives the following [(w1,1),(w1,1),(w2,1)] ==> [(w1,2),(w2,1)].
Following that we collect the output and print it as words with their counts.
How about getting the words that are mentioned more than 10 times? You could try to modify the above code using the filter transformation to get only the words that have 10 of more mentions in our output file. To do that we need to chain .filter(lambda x: x[1]>=10) after the reduceByKey function:
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda x,y:x+y)\
.filter(lambda x: x[1]>=10)
The output we get includes the word Spark as expected along with some common stop words:
...... : 75 to: 14 the: 21 for: 11 Spark: 15 and: 10 ......
In this post we saw how we apply transformations to Spark RDD using the python api PySpark. We also dug up a little into the details of the transformations in a useful wordcount example. Next we will look at more involved transformations available to use in the Spark API.
